
Кратко
- Старые программы вроде Audacity убирали вокал через вычитание каналов или вырез средних частот. Работало плохо: вместе с голосом пропадали бас-бочка и малый барабан, а сам вокал оставался призраком на громких нотах.
- Нейросеть работает иначе. Её обучают на парах «готовый микс» и «та же песня по отдельным дорожкам». Модель миллионы раз сравнивает, что должно остаться в инструментале, и учится узнавать вокал как явление, а не как диапазон частот.
- Прорыв случился в 2019 году. Deezer выложила в открытый доступ Spleeter, через пару лет вышел Demucs от исследователей Meta. С этого момента качественное разделение стало доступно кому угодно, а не только студиям с дорогим софтом.
- В Сонграйтере эта технология встроена в чат. Отправляете mp3 боту, нажимаете «Разделить», и через 2-3 минуты получаете два файла: чистый вокал и инструментал. Стоит около 12 рублей за трек.
- Нейросеть хорошо справляется с современными студийными записями и путается на старых моно-плёнках и плотной полифонии. Это честное ограничение технологии, а не недоработка конкретного сервиса.
- Открыть Сонграйтер → — выбрать МАХ, Telegram или веб-версию в один клик. Демо первой песни бесплатно.
Почему раньше вокал убирался так плохо
 Раньше разделение дорожек делали вручную через эквалайзер и фазовую инверсию: час работы ради посредственного результата.
Раньше разделение дорожек делали вручную через эквалайзер и фазовую инверсию: час работы ради посредственного результата.
Если вы хоть раз пробовали убрать голос из песни в Audacity лет десять назад, вы помните разочарование. Открываешь стерео-файл, ищешь в меню «Vocal Reduction and Isolation», жмёшь, и получаешь странную кашу.
Старый метод работал на одном допущении. В большинстве записей вокал сведён по центру, то есть звучит одинаково в левом и правом канале. Программа разворачивала один канал по фазе и складывала с другим. Всё, что было строго по центру, взаимно уничтожалось. Вокал действительно становился тише.
Беда в том, что по центру сидит не только голос. Там же бас, бочка, малый барабан, иногда соло-инструмент. Вся ритм-секция улетала в тишину вместе с вокалом. Получался не минус, а инструментал без низа и без удара, играть под такое невозможно.
Был и второй подход, через эквалайзер. Голос человека живёт примерно в диапазоне от 300 Гц до 3 кГц. Логика простая: вырезаем эту полосу, вокал пропадает. На практике в этой же полосе сидят гитара, клавиши, скрипка, добрая половина аранжировки. Срезаешь голос, срезаешь и музыку. А обертоны вокала, которые тянутся выше 3 кГц, никуда не деваются, и на форте голос всё равно слышно призраком.
Честно говоря, оба метода были не «удалением вокала», а компромиссом. Для караоке дома под настроение сходило. Для записи кавера или нормального минуса уже нет.
Как нейросеть учится узнавать голос
Нейросеть подошла к задаче с другой стороны. Она не вычитает каналы и не режет частоты. Она учится понимать, что в звуке является вокалом, а что нет.
Объясню на принципе обучения. Чтобы натренировать модель, нужен датасет из тысяч песен, для каждой из которых есть две версии: финальный сведённый микс и тот же трек, разложенный на отдельные дорожки (голос, барабаны, бас, остальное). Такие наборы существуют, самый известный называется MUSDB18, его собрали специально для исследований по разделению источников звука.
Дальше начинается тренировка. Модель получает на вход микс и пытается предсказать, как звучит изолированный вокал. Сначала угадывает плохо. Алгоритм сравнивает её догадку с настоящей вокальной дорожкой, считает ошибку и корректирует внутренние веса. Потом ещё раз. И ещё миллион раз, на разных песнях, разных голосах, разных жанрах.
Постепенно сеть нащупывает закономерности, которые человек словами не сформулирует. Как ведёт себя вибрато. Как устроены согласные и шипящие. Чем дыхание певца отличается от шороха тарелки. Какие гармоники сопровождают человеческий голос, а какие принадлежат синтезатору. Модель не «знает» музыку в нашем смысле, но она видела столько примеров, что научилась статистически отделять одно от другого.
Технически современные модели работают со спектрограммой. Это картинка, где по горизонтали время, по вертикали частота, а яркость показывает громкость. Для нейросети звук превращается в изображение, а разделение вокала и музыки становится задачей, похожей на то, как зрительная сеть обводит кошку на фото. Она строит маску: вот эти пиксели спектрограммы относятся к вокалу, эти к инструменталу. По маске восстанавливаются два отдельных аудиофайла.
Поэтому AI-разделение не глухое к контексту. Если бочка и голос звучат одновременно на одной ноте, частотный фильтр их не различит в принципе. Нейросеть различает, потому что узнаёт не частоту, а характер звука.
Spleeter и Demucs: момент, когда всё изменилось
 Spleeter от Deezer и Demucs от исследователей Meta: открытые модели, на которых построено почти всё современное разделение дорожек.
Spleeter от Deezer и Demucs от исследователей Meta: открытые модели, на которых построено почти всё современное разделение дорожек.
Технология разделения источников разрабатывалась в академических лабораториях ещё в 2000-х, но обычному человеку она была недоступна. Всё поменялось в конце 2019 года.
Стриминговый сервис Deezer выложил в открытый доступ инструмент под названием Spleeter. Это была обученная нейросеть, которая разбирала трек на 2, 4 или 5 дорожек, работала быстро и, главное, бесплатно. Любой разработчик мог скачать её и встроить в своё приложение. Качество по тем временам казалось фантастикой: то, за что студии платили деньги, теперь раздавали даром.
Через год с небольшим исследователи из Meta (тогда ещё Facebook) опубликовали Demucs. Архитектура другая, и на многих треках результат заметно чище, особенно по части баса и барабанов. Demucs несколько раз обновлялся, появлялись новые версии, и сейчас он считается одной из сильнейших открытых моделей для этой задачи.
Что это дало на практике. Почти все онлайн-сервисы, которые сегодня предлагают «убрать вокал» или «сделать минус», используют либо Spleeter, либо Demucs, либо их доработанные версии, либо собственные модели, построенные по тем же принципам. LALAL.ai, например, выросла как самостоятельный SaaS именно на волне этого спроса. Сама технология стала общедоступной, и разница между сервисами теперь не в том, «есть ли у них нейросеть», а в том, насколько удобно ей пользоваться и насколько дообучена конкретная модель.
Для пользователя вывод простой. Если сервис обещает разделение через нейросеть, скорее всего, фундамент у него один и тот же. Смотреть стоит на удобство, цену и на то, как сервис ведёт себя на ваших конкретных файлах.
Чем AI-разделение реально отличается от старых фильтров
Разница не косметическая, она принципиальная. Соберу основные пункты, по которым нейросеть обходит частотный подход.
Старый фильтр работает с сигналом вслепую. Он не знает, что перед ним за музыка, он просто механически режет полосу частот или вычитает каналы. Нейросеть работает с пониманием. Она видела тысячи песен и предсказывает, как должен звучать вокал именно в этом контексте.
Частотный метод не различает инструменты, которые делят одну полосу с голосом. Гитара в диапазоне голоса для него неотличима от голоса. Нейросеть различает по тембру и характеру атаки, поэтому гитара остаётся в инструментале, а голос уходит в вокальную дорожку.
Старый метод губил стерео-картину. После фазовой инверсии трек часто звучал плоско, потому что вся центральная информация исчезала. Нейросеть восстанавливает обе дорожки как полноценные стерео-файлы, панорама сохраняется.
Ещё один момент, призрачный вокал. У частотного фильтра обертоны голоса всегда оставались, и на громких нотах певца было слышно. Нейросеть убирает голос целиком, вместе с верхними гармониками. На хорошем исходнике в минусе не остаётся ничего, кроме разве что лёгкого хвоста на самых форсированных нотах.
И последнее. Старый софт требовал, чтобы вы понимали, что делаете: какие частоты резать, на сколько децибел, в каком канале. Нейросеть не требует ничего. Вы отдаёте ей файл, она отдаёт вам результат. Вся сложность спрятана внутри модели.
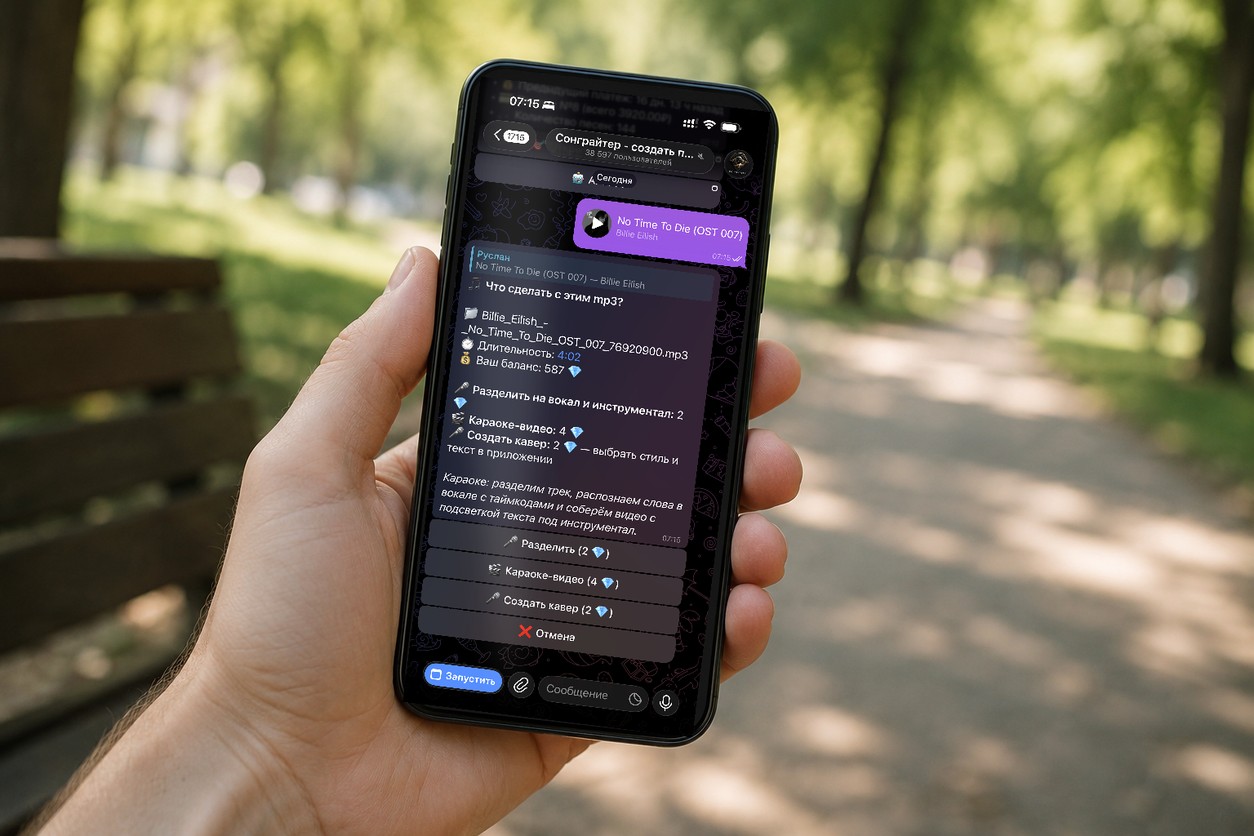
Как удалить вокал нейросетью в Сонграйтере
В Сонграйтере разделение работает прямо в чате, без сайтов, программ и регистраций. Три шага.
Шаг 1. Открыть бот. Зайдите в Сонграйтер через удобный канал:
- Мини-приложение в МАХ — самый стабильный канал для пользователей в России
- Telegram-бот @easysongbot — для привычного мессенджера
- Веб-версия easysong.ru/app — открывается в любом браузере
Шаг 2. Отправить трек. Перетащите mp3 в чат боту или прикрепите его как документ. Поддерживаются mp3, wav, ogg, flac, aac, m4a и даже mp4, всего семь форматов. Ограничение на размер файла около 20 МБ, этого хватает на трек длиной до 20 минут в нормальном битрейте.
Шаг 3. Нажать «Разделить». Под загруженным файлом появится кнопка разделения. Жмёте, и через 2-3 минуты в чат приходят два файла: дорожка с чистым вокалом и инструментал, то есть готовый минус. Скачиваете оба.
Стоит это 2 алмаза, что на максимальном пакете со скидкой 20% выходит около 12 рублей за трек. Обычная цена без скидки составляет 24 рубля за разделение. Демо первой песни в сервисе бесплатное, так что протестировать звук можно без оплаты.
Есть приятная деталь. Если этот же аудиофайл уже разделял кто-то раньше, результат берётся из кэша, и для вас разделение всегда стоит фиксированные 2 алмаза, без надбавки за длину. Для популярных треков это работает почти всегда.
Подробный разбор всех нюансов есть в нашем гайде «Убрать вокал из песни онлайн». А полная инструкция по теме минуса со сравнением сервисов лежит на странице «Как сделать минус из песни нейросетью».
Выделить голос из песни отдельно — для каверов и обучения вокалу
Иногда задача обратная. Нужен не минус, а наоборот, чистый вокал оригинала. Кавер-исполнитель разбирает на слух, как именно поёт солист: где он берёт дыхание, как тянет долгие гласные, в каких местах добавляет хрипотцу. С полным миксом такое не услышишь, барабаны и гитары перекрывают тонкие детали. А когда голос остаётся отдельным файлом, всё становится очевидным.
Преподавателям вокала такая дорожка тоже полезна. Можно показать ученику, как звучит постановка фразы у конкретного артиста, разложить её по нотам, повторить попытку за попыткой, не отвлекаясь на аранжировку. Голос на изучение, без музыкального фона, превращается в обычный учебный материал — как препарат под микроскопом.
Отдельный сценарий — AI-каверы. Сейчас многие тренируют голосовые модели по эталонным записям любимых артистов, и для тренировки нужна чистая вокальная дорожка без музыки. Чем чище вокал отдельным файлом, тем лучше получится модель.
В Сонграйтере не нужно выбирать, что выделить. После нажатия кнопки «Разделить» сервис всегда отдаёт оба файла сразу. Vocal.mp3 — это чистый голос без музыки. Instrumental.mp3 — только музыка без голоса. Скачиваете тот, что нужен под задачу, или оба, если планируете и кавер записать, и под минус потренироваться. Цена одна за разделение, не по 2 алмаза за каждый файл.
Маленькая оговорка про качество. Чистый вокал получается лучше всего на современных записях с хорошей студийной обработкой. На старых треках 70-80-х голос может приходить с лёгкими хвостами реверберации или фоном гитары — это особенность исходника, а не сервиса. Подробнее о том, какие сервисы умеют выделять вокал и чем они отличаются, рассказано на странице «Как сделать минус из песни нейросетью».
Что нейросеть делает хорошо, а где ошибается
 Качество разделения напрямую зависит от исходника: чистая студийная запись разбирается почти идеально, старая моно-плёнка ставит нейросеть в тупик.
Качество разделения напрямую зависит от исходника: чистая студийная запись разбирается почти идеально, старая моно-плёнка ставит нейросеть в тупик.
Будет честно сказать прямо: нейросеть не волшебная палочка. Она хорошо справляется с одними записями и плохо с другими, и важно понимать, где граница.
Где нейросеть работает почти идеально. Современные студийные записи, примерно от 2010 года и новее. Стереозапись, вокал сведён по центру, битрейт от 192 кбит. На таком материале разделение получается чистое: в минусе остаётся, может быть, 5-10 процентов еле слышного хвоста вокала на самых громких нотах, и то если прислушиваться. Поп, рок, рэп, электроника последних лет, всё это разбирается отлично.
Где начинаются проблемы. Старые записи 60-80-х годов, особенно моно. Там вокал и инструменты физически не разнесены по каналам, всё в одной точке, и нейросеть путается. Часть гитары может уехать в вокальную дорожку, часть голоса остаться в инструментале. Низкий битрейт усугубляет: если у вас mp3 на 64 кбит, скачанный когда-то с торрента, исходных данных для чистого разделения просто нет.
Сложная полифония это отдельная история. Хор, где поют десять человек, дабл-трек вокал, оперные арии с плотным оркестром. Тут модель тоже спотыкается, потому что граница между «вокалом» и «не вокалом» размывается. Это не недостаток конкретного сервиса, это предел самой технологии на текущем этапе. По моему опыту, на плотном хоре ни один доступный сейчас инструмент не даёт идеального результата.
Лайфхак для старых записей. Прогоните файл через шумоподавитель (это бесплатно делается в той же Audacity) до загрузки в Сонграйтер. Уберёте самый агрессивный фоновый шум, и нейросети будет легче. Чудес не ждите, но станет заметно чище.
Если коротко: качество результата примерно равно качеству исходника. Хороший файл на входе даёт хороший минус на выходе.
Куда движется технология
Технология разделения звука развивается быстро, и за последние пару лет произошло несколько заметных сдвигов.
Первое, стемов становится больше. Если Spleeter в 2019 году делил трек на 2-5 дорожек, то новые модели уже умеют выделять отдельно бас, ударные, гитару, клавиши, бэк-вокал. Профессиональные сервисы вроде Moises и LALAL.ai на платных тарифах предлагают разделение на 10-11 стемов. В Сонграйтере базовое разделение даёт вокал и инструментал, но Pro-режим с разбором на 11 дорожек тоже есть, стоит он 8 алмазов.
Второе, растёт качество на сложном материале. Модели постепенно учатся лучше работать с тем, на чём раньше спотыкались: с моно-записями, с плотными аранжировками. Прогресс не мгновенный, но он есть.
Третье, скорость. То, что Spleeter делал за минуты, новые оптимизированные модели делают почти в реальном времени. Это открывает дорогу к live-разделению, когда вокал убирается прямо во время воспроизведения.
Куда это всё идёт в целом. Разделение источников перестаёт быть отдельной функцией и встраивается в более крупные сценарии. Сделать минус, тут же записать поверх свой голос, собрать караоке-видео, всё в одном месте, без скачивания файлов туда-сюда. Сонграйтер движется именно в эту сторону: разделение это не конечная точка, а один из инструментов в общем наборе для работы с музыкой.
Открыть Сонграйтер → поможет выбрать МАХ, Telegram или веб одним кликом, без регистрации картой.
FAQ
Как именно нейросеть удаляет вокал из песни?
Нейросеть обучают на тысячах пар «готовый микс» и «тот же трек по отдельным дорожкам». Сравнивая их миллионы раз, модель учится узнавать вокал по тембру и характеру звука, а не по диапазону частот. Потом она строит маску и восстанавливает по ней две дорожки: голос и инструментал.
Чем AI-разделение лучше функции удаления вокала в Audacity?
Audacity убирает голос через вычитание каналов или вырез средних частот. Вместе с вокалом пропадает ритм-секция, а сам голос остаётся призраком на громких нотах. Нейросеть различает инструменты по характеру звука, поэтому минус получается полноценным, со всем низом и ударными.
Что такое Spleeter и Demucs?
Это две открытые нейросетевые модели для разделения музыки на дорожки. Spleeter в 2019 году выложила в открытый доступ компания Deezer, Demucs позже опубликовали исследователи Meta. На них или их доработках построено большинство современных сервисов для создания минусов.
Сколько стоит удалить вокал в Сонграйтере?
Разделение стоит 2 алмаза. На максимальном пакете со скидкой 20% это около 12 рублей за трек, обычная цена без скидки составляет 24 рубля. Демо первой песни в сервисе бесплатное. Если файл уже разделяли раньше, результат берётся из кэша по фиксированной цене.
Почему минус из старой песни получается грязным?
В старых записях, особенно моно, вокал и инструменты не разнесены по каналам, всё звучит из одной точки. Нейросети не за что зацепиться, и она путается: часть голоса остаётся в минусе, часть инструментов уезжает в вокал. Низкий битрейт исходника делает только хуже.
Можно ли получить чистый вокал, а не минус?
Да, нейросеть разделяет трек на обе дорожки сразу. Вы получаете и инструментал, и изолированный вокал. Чистый вокал, или акапелла, нужен для ремиксов, тренировки звукорежиссёров и извлечения текста песни через сервисы распознавания речи.
На каких платформах работает Сонграйтер?
Сервис открывается через три канала, аккаунт и алмазы общие:
- Мини-приложение в МАХ — самый стабильный для российских пользователей
- Telegram-бот @easysongbot — для тех, кто живёт в Telegram
- Веб-версия easysong.ru/app — открывается в любом браузере
Что почитать дальше
- Как создать песню нейросетью — pillar-страница с пошаговым разбором: от описания идеи до готового MP3 за пять минут.
- Песни нейросети — топ-30 в чарте — живая подборка треков по числу лайков, можно сравнить разные жанры и голоса.
- Каталог артистов Сонграйтера — авторы и их альбомы, отсортировано по жанрам и активности.
- Как сделать минус из песни нейросетью — главная страница по теме со сравнением 6 сервисов
- Убрать вокал из песни онлайн — пошаговый разбор для главного клиентского сценария
- Сделать минус в хорошем качестве — что влияет на чистоту разделения и как добиться лучшего результата
- Vocal remover на русском — что такое vocal remover и какая есть русскоязычная альтернатива


